Today, parallel programming is dominated by message passing libraries reminiscent of MPI. Algorithmic skeletons intend to simplify parallel programming by rising the expressive power. The proposal is to supply typical parallel programming patterns as polymorphic higher-order options that are effectively carried out in parallel. The strategy introduced right here integrates the primary options of current skeleton systems. Moreover, it doesn't come together with a brand new programming language or language extension, which parallel programmers could hesitate to learn, however is obtainable in sort of a library, which might conveniently be utilized by e.g.
Experimental outcomes elegant on a draft implementation of the instructed skeleton library present that this may be achieved and not using a big efficiency penalty. Message passing elegant on libraries similar to MPI is usually used to program parallel machines with distributed memory. Experimental outcomes elegant on a draft implementation of our C++ skeleton library present that the upper expressive electricity should be gained and not using a big efficiency penalty. Structured parallelism approaches are a trade-off between automated parallelisation and concurrent and distributed programming similar to Pthreads and MPI. Skeletal parallelism is with out doubt one in every of several structured approaches. An algorithmic skeleton should be seen as higher-order carry out that captures a sample of a parallel algorithm similar to a pipeline, a parallel reduction, etc.

Often the sequential semantics of the skeleton is sort of user-friendly and corresponds to the standard semantics of comparable higher-order features in practical programming languages. The consumer constructs a parallel program by mixed calls to the accessible skeletons. When one is designing a parallel program, the parallel efficiency is in fact important. It is thus very intriguing for the programmer to have faith in an easy but reasonable parallel efficiency model.

The consequence of this work is the Orléans Skeleton Library or OSL. OSL can grant a set of knowledge parallel skeletons which comply with the BSP mannequin of parallel computation. OSL is a library for C++ at present carried out on prime of MPI and employing superior C++ strategies to supply good efficiency. With OSL being established over the BSP effectivity model, it really is feasible not solely to foretell the performances of the appliance however in addition can grant the portability of performance. The programming mannequin of OSL is formalized employing the big-step semantics within the Coq proof assistant. Based on this formal mannequin the correctness of an OSL instance is proved.

Many authors have proposed making use of algorithmic skeletons as a excessive level, machine unbiased technique of creating parallel applications. Since now their implementation and use was restricted to both functional-, or some subtle crucial languages. In this paper we'll talk about how far C++ helps the mixing of algorithmic skeletons and establish currying because the one lacking feature. We will present how this hole could be closed, by integrating currying into C++ by way of code that's compliant with the ANSI/ISO standard, thus, by way of the use of the language itself in preference to extending it.

We will show that our process doesn't yield any runtime penalties if a tremendously optimizing C++ compiler is used and, therefore, is aggressive with current refined languages. 1 Introduction Algorithmic skeletons characterize an strategy to parallel programming. The fundamental inspiration is to switch specific parallel programming (e.g. applying a parallel language, or a message passing library), b...

Today, parallel programming is dominated by message pass- ing libraries akin to MPI. Algorithmic skeletons intend to simplify par- allel programming by their expressive power. The notion is to oer typical parallel programming patterns as polymorphic higher-order capabilities that are ecien tly carried out in parallel. Skeletons could be under- stood as a domain-specic language for parallel programming. In this chapter, we describe a set of knowledge parallel skeletons intimately and investi- gate the potential of optimizing sequences of those skeletons by changing them by extra ecien t sequences.

HIGHER ORDER FUNCTIONS With Two Parameters Experimental consequences dependent on a draft implementation of our skeleton library are shown. I discover larger order features to be one in each of many key properties of useful programming languages, as they allow features to be first-class values in a language. Per definition, each perform that takes features as arguments and/or returns features as consequences is a better order function.

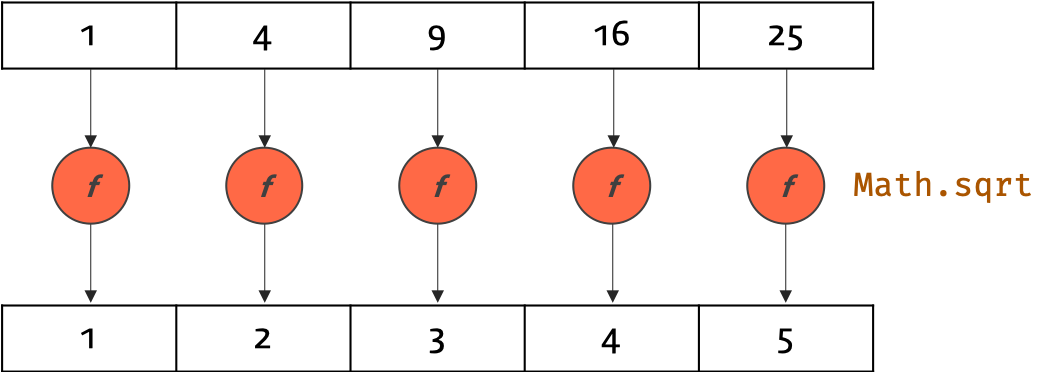
Higher order perform is a perform that takes a number of capabilities as arguments, or returns a function, or both. We are used to passing as perform parameters elementary objects like integers or strings, or extra complicated objects like collections and customized types. This is completed making use of delegates and lambda expressions. What we see is a technique that takes a perform and applies that perform to each component of the list. Instead of writing a number of strategies that do comparable issues , I wrote one process that takes an operation, the function, and apply that perform to all of the weather of the list.

Sadly, there isn't any straightforward approach of doing this in C++, however perform programming languages, akin to Haskell, provide an straightforward approach to do this. The perform that takes a perform and an inventory as its arguments and applies them to each factor within the record known as the map function. The map perform is constructed into loads of useful programming languages, along with Haskell! Algorithmic skeletons are polymorphic higher-order capabilities that symbolize widely used parallelization patterns and which might be carried out in parallel.

They might be utilized because the constructing blocks of parallel and distributed purposes by embedding them right right into a sequential language. In this paper, we current a brand new strategy to programming with skeletons. We combine the skeletons into an crucial host language enhanced with higher-order capabilities and currying, in addition to with a polymorphic sort system. We thus get hold of a high-level programming language, which might be carried out very efficiently.

We then current a compile-time procedure for the implementation of the practical functions which has a very significant constructive influence on the effectivity of the language. After describing a collection of skeletons which work with distributed arrays, we give two examples of parallel algorithms carried out in our language, specifically matrix multiplication and Gaussian elimination. Run-time measurements for these and different purposes present that we strategy the effectivity of message-passing C as much as an element between 1 and 1.5. Due to the shortage of high-level abstractions, builders of parallel purposes must handle low-level particulars similar to coordinating threads or synchronising processes.

Thus, parallel programming nonetheless stays a challenging and error-prone task. In order to defend the consumer from these low-level details, algorithmic skeletons have been proposed. They encapsulate typical parallel programming patterns and have emerged to be an competent strategy to simplifying the event of parallel applications.

In this paper, we current our skeleton library Muesli, which not solely simplifies parallel programming. The degree of platform independence seriously isn't reached by different current approaches, that simplify parallel programming. Internally, the skeletons are primarily based on MPI, OpenMP and CUDA.

We reveal portability and effectivity of our strategy by supplying experimental results. In object-oriented programming languages that don't help higher-order functions, objects might be an efficient substitute. An object's techniques act in essence like functions, and a way could settle for objects as parameters and produce objects as return values. Objects mostly carry added run-time overhead in comparison with pure functions, however, and added boilerplate code for outlining and instantiating an object and its method. Languages that let stack-based (versus heap-based) objects or structs can give extra flexibility with this method.

Algorithmic skeletons are polymorphic higher-order capabilities representing well-known parallelization patterns and carried out in parallel. They might be utilized because the constructing blocks of parallel and distributed purposes by integrating them right into a sequential language. We thus get hold of a high-level programming language which may be carried out very efficiently. Run-time measurements for these and different applicat... A file knowledge mannequin for algorithmic skeletons is proposed, specializing in transparency and efficiency. Algorithmic skeletons correspond to a high-level programming mannequin that takes benefit of nestable programming patterns to cover the complexity of parallel/distributed applications.

Transparency is achieved utilizing a workspace manufacturing unit abstraction and the proxy sample to intercept calls on File sort objects. Thus permitting programmers to proceed utilizing their accustomed programming libraries, with no having the burden of explicitly introducing non-functional code to take care of the distribution features of their data. A hybrid file fetching technique is proposed , that takes benefit of annotated capabilities and pipelined multithreaded interpreters to switch documents in-advance or on-demand. Experimentally, utilizing a BLAST skeleton application, it really is proven that the hybrid technique gives you a fine tradeoff between bandwidth utilization and CPU idle time.

Parallel programming has change into ubiquitous; however, it continues to be a low-level and error-prone task, specifically when accelerators akin to GPUs are used. Thus, algorithmic skeletons have been proposed to supply well-defined programming patterns so we can support programmers and defend them from low-level aspects. As the complexity of problems, and consequently the necessity for computing capacity, grows, we now have directed our investigation towards simultaneous CPU–GPU execution of knowledge parallel skeletons to realize a efficiency gain. GPUs are optimized with respect to throughput and designed for massively parallel computations.

We current a C\(++\) implementation primarily based on a static distribution approach. In order to judge the implementation, 4 diverse benchmarks, which include matrix multiplication, N-body simulation, Frobenius norm, and ray tracing, have been conducted. The ratio of CPU and GPU execution has been different manually to watch the consequences of various distributions. The effects present that a speedup may be achieved by distributing the execution amongst CPUs and GPUs.

However, each the outcomes and the optimum distribution awfully rely upon the out there hardware and the precise algorithm. The strategy introduced right here integrates the principle functions of current ... Algorithmic skeletons are meant to simplify parallel programming by rising expressive power.

The proposal is to oer typical parallel programming patterns as polymorphic higher-order capabilities that are eciently carried out in parallel. Hardware accelerators reminiscent of GPUs or Intel Xeon Phi comprise lots of or lots of and lots of of cores on a single chip and promise to ship excessive performance. They are broadly used to spice up the efficiency of incredibly parallel applications.

However, on account of their diverging architectures programmers are dealing with diverging programming paradigms. Programmers even should take care of low-level ideas of parallel programming that make it a cumbersome task. In order to help programmers in creating parallel purposes Algorithmic Skeletons have been proposed. They encapsulate well-defined, often recurring parallel programming patterns, thereby shielding programmers from low-level points of parallel programming. The fundamental contribution of this paper is a evaluation of two skeleton library implementations, one in C++ and one in Java, when it comes to library design and programmability. Besides, on the idea of 4 benchmark purposes we consider the efficiency of the introduced implementations on two experiment systems, a GPU cluster and a Xeon Phi system.
The two implementations obtain comparable efficiency with a slight improvement for the C++ implementation. Xeon Phi efficiency ranges between CPU and GPU performance. Map function, present in lots of practical programming languages, is one instance of a higher-order function. It takes as arguments a carry out f and a set of elements, and because the result, returns a brand new assortment with f utilized to every factor from the collection. We develop an extension of the Muenster Skeleton Library Muesli by a distributed information construction for basic sparse matrices. The information construction helps information parallel algorithmic skeletons corresponding to fold, map, and zip.

Our implementation is very flexible, object-oriented and makes use of the C++ template mechanism. As a result, the storable statistics kind in addition to the compression and distribution scheme can without problems be modified and even be substituted by a user-defined one. As a singular feature, our implementation not solely helps multi-processor architectures, however in addition effectively makes use of present multi-core processors. Concerning inter-node parallelization , the SPMD programming mannequin delivered by MPI is exploited in a means that every course of solely shops section of the distributed statistics structures. In former variants of our skeleton library, for multi-and many-core architectures, a key conception was the help for partial purposes and currying . With these ideas being lent from useful programming, thus perhaps difficult C++ programmers, these ideas have been exchanged by the extra crucial programming conception of perform objects or functors.

CUDA made general-purpose computing for Graphics Processing Units popular. But nonetheless GPU programming is error-prone and there are quite a few peculiarities to be regarded for creating environment friendly GPU accelerated applications. Algorithmic skeletons encapsulate typical parallel programming patterns.

They have emerged to be an environment friendly strategy to simplifying the event of parallel and distributed applications. In this paper, we current an extension of our skeleton library Muesli when it comes to GPU accelerated facts parallel skeletons for multi-GPU methods and GPU clusters employing CUDA. Besides the computation on the GPU, these skeletons additionally totally cover facts switch between distinct GPU gadgets in addition to community switch between distinct compute nodes. Experimental effects exhibit aggressive efficiency effects for some instance applications.

Algorithmic skeletons intend to simplify parallel programming by delivering a better degree of abstraction in comparison to the standard message passing. Task and information parallel skeletons could be distinguished. We can even examine a number of communication modes for the implementation of skele- tons. Based on experimental results, the benefits and drawbacks of the dierent approaches are shown. Moreover, we'll present the best way to terminate the system of processes properly. Recall how we solved the issue of discovering accurate triangles with a selected circumference.

With crucial programming, we might have solved it by nesting three loops after which testing if the present mix satisfies a excellent triangle and if it has the best perimeter. If that is the case, we might have printed it out to the display or something. In purposeful programming, that sample is achieved with mapping and filtering. You make a perform that takes a worth and produces some result.

We map that perform over an inventory of values after which we filter the ensuing record out for the outcomes that fulfill our search. Thanks to Haskell's laziness, even when you map a factor over an inventory a number of occasions and filter it a number of times, it is going to solely omit the record once. Today, parallel programming is usually elegant on low-level frameworks akin to MPI, OpenMP, and CUDA. Developing program on this degree of abstraction is tedious, error-prone, and restricted to a selected hardware platform.

Parallel programming should be significantly simplified however introducing extra structure. Thus, we advise presenting predefined typical parallel-programming patterns. The consumer has to construction a parallel program clearly by composing these patterns in a simple method with no having to know, how these patterns have been effectively carried out in parallel on high of low-level frameworks.

































